Minimizing the Pain of Lockstep Multiplayer
Posted: November 23rd, 2015 | Author: Dan | Filed under: Rapture | 3 Comments »Written by Tundra Games CTO Andrew Weinkove
Rapture World Conquest is free to download here for iOS and here for Android
Our previous blog about going free can be found here
Introduction
Rapture – World Conquest was released on iOS in September 2014 as a single player only game. Multiplayer was implemented later and was added in an update in March 2015. The game was released for Android at the end of October 2015.
Any programmer who has ever grafted multiplayer functionality onto a single player game will tell tales of just how difficult the process can be. For Rapture, the process went relatively smoothly because we planned ahead for lockstep multiplayer and built in a number of systems from the start.
To coincide with the recent release of our Android version we have written this article to talk about the systems and processes we put in place that minimized the pain of lockstep.
Choosing Lockstep
The idea behind lockstep multiplayer is simple, if every player shares their input with every other player, the simulation can be run on everyone’s machines with identical input to produce identical output.[1]
Lockstep multiplayer has become somewhat unfashionable these days as server/client approaches offer many advantages in a lot of genres [2][3]. The key advantage of lockstep is its low bandwidth demands, the key disadvantage is high lag as the simulation can’t step forward until a machine has received the input from all of the players. With audiences generally having access to decent broadband, the attractiveness of low bandwidth requirements typically looks insignificant against the usability cost of high lag.
However, the real-time strategy (RTS) genre is something of an exception. Latency in an RTS typically doesn’t affect usability anywhere near as much as it might in other genres like first person shooters. Meanwhile, massive numbers of units mean that alternatives to lockstep can easily use prohibitive amounts of bandwidth even on good connections.
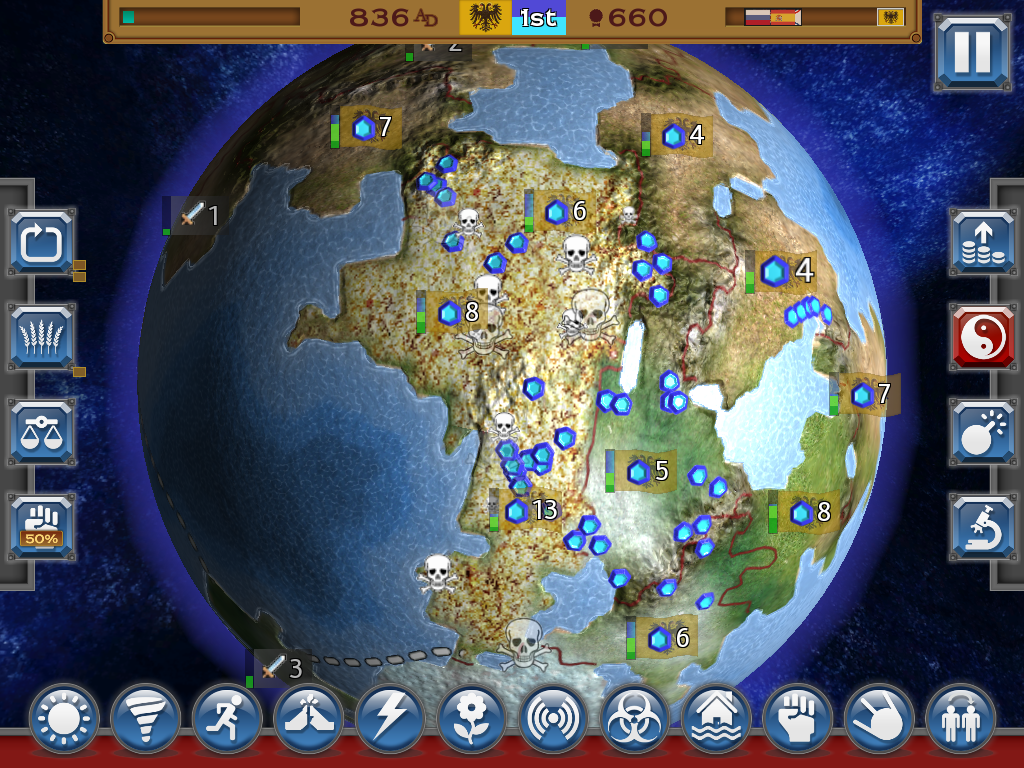
Even in the RTS genre, lockstep is not the only option[4], however lockstep is especially attractive to mobile developers because cellular and bluetooth connections can be extremely poor relative to the broadband connections that PC and console developers can generally rely upon.
For these reasons, we decided early on that Rapture – World Conquest would use lockstep multiplayer, and we planned for it from the start.
Desynchronisation
Although the idea of lockstep is very simple, in practise it can be very challenging to keep the simulation running in perfect synchronisation. The code that drives your game logic must be fully deterministic across all the machines that will play against each other. That is, the machines must run the exact same set of calculations based on the exact same set of inputs and produce the exact same results. Any tiny variation between machines will cause knock-on effects so that after a short period of time the game state on different machines is totally different with no mechanism to bring them back into sync.
When variations occur, it is known as a desynchronisation bug, and in common with most lockstep games we share checksums of the game state between machines to detect desynchronisation and treat checksum mismatches similarly to network errors by stopping the game and displaying an appropriate message.
Desynchronisation bugs can be extremely difficult to track down, often requiring hours or days of debugging[5], so any steps that can be taken to catch these bugs early are very valuable. In the following paragraphs we discuss the strategies that we used to address these bugs as early as possible during development.
Code Organization
One of the simplest but often forgotten steps that we took was to organize our code to make it obvious which systems needed to be fully deterministic for lockstep. We refer to the section of our code that must run in lockstep as ‘the simulation’ and tried to make a clear distinction between simulation code and ordinary code.
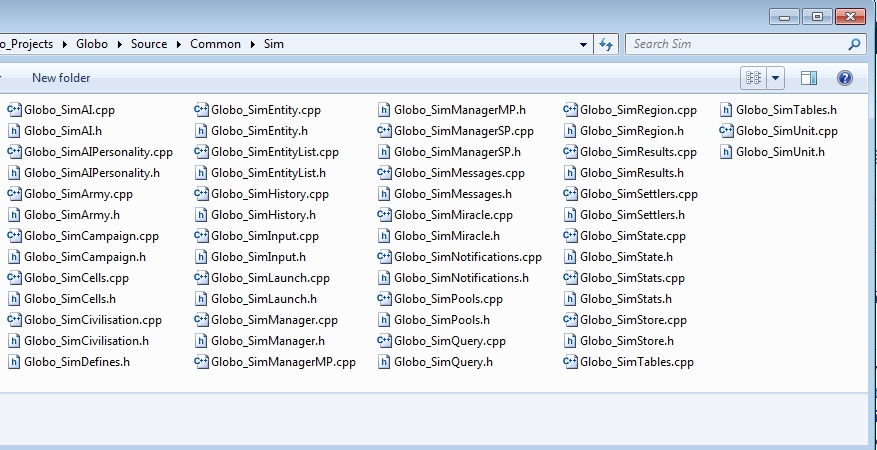
All the simulation code source files were put under a directory called ‘Sim’ and have the word ‘Sim’ in their filename. We made sure coders knew to be extra careful when making modifications to the simulation, and regularly reviewed checkins on this directory for potential issues. We also compiled all our code with a high warning level, which can help highlight some programming errors like uninitialized variables which can lead to desyncs.
Fixed Timestep Updates
When we talk about all machines having to run from the same input, the immediate thought is of button presses or commands produced through the UI. In fact, the timestep is another important input into the simulation.

Right from the start we designed our simulation to run at a fixed timestep with interpolation[6]. In common with lots of other RTS games, we run our simulation at quite a low tick rate, 10hz in our case, and interpolation allows the rendering to run at a fast smooth framerate.
This decoupling of the simulation loop from the render loop not only achieves the fixed timestep necessary for lockstep, but it also reduces CPU load by letting the complex simulation run at a lower rate.
At the same time, we also engineered our code to run the simulation on a separate thread. This has little to do with lockstep, but was great for performance as it can conceal the large CPU spikes when hundreds of units pathfind on the same frame, and also takes advantage of the multicore processors that most modern mobile devices have.
Random Numbers
Another area that can produce desyncs is random number generation. We needed to ensure that every machine is generating the same set of pseudo random numbers otherwise multiplayer matches would quickly go out of sync.

Right from the start we made sure that our simulation used an independent random number generator from the rest of the game. This is because the game might be running at different framerates on different machines, so any random number generation in our rendering code (a particle emitter for example) will be called a different number of times across machines. Obviously, the random number seed used by the simulator needs to be agreed upon by all machines and we did this by generating a seed from a checksum of the shared launch settings.
Deciding to Prohibit Floating Point Math
Floating point numbers can present something of a problem. The challenge is that while the IEEE standards set out maximum errors for floating point calculations, individual implementations (either hardware implementations of maths operations or software implementations of functions like sine) have scope for producing slightly different results. These results won’t be very different, they’ll vary only occasionally and usually only by a very small amount. However, that is enough to upset the delicate balancing act of a lockstep game.

Now, to be clear, floating point math is not vague and indeterminate. We would always get the same result when running the same executable on the same hardware. The problems arise when running on different hardware, using a different compiler, or using different compiler settings.
It probably isn’t very productive to delve too deeply into issues surrounding cross-hardware floating point determinism as it seems to be a topic that can cause some passionate disagreement and many good articles cover this ground [7][8][9]. Suffice to say that while games exist which use floats and run without desync across a variety of PC architectures, no-one has made the claim that it is an easy path to tread.
We decided that attempting to use floats in areas of our code that need to be deterministic would be a world of pain that is best avoided. Further to that, we were unsure if all the different FPUs found in mobile devices can actually be coerced to produce identical floating point results in the same way that PC FPUs can.
Finally, we’d set ourselves a target of supporting cross platform play during development. Having decided to support 4 player matches, it makes testing and debugging a lot easier if we can mix and match PC, OSX, Android and iOS builds with differing optimisation levels. Achieving flexible cross platform play like this just would not have been possible with floating point maths in our simulation.
Enforcing the Prohibition of Floating Point Math
Having decided not to use floating point math, we naturally decided to use fixed point math in its place. The idea is simple enough, we have a class that represents fixed point numbers, it’s simply a 32-bit integer where the bottom 12 bits represent the fractional part. So, the number 4096 represents 1.0, 2048 represents 0.5. Multiplying two fixed point numbers together would look something like ((FixedA * FixedB) >> 12), although all of our actual functions have a lot of checks to avoid preventable overflows and assert about unavoidable ones. We looked around for an existing fixed point math library that could be plugged in easily, but didn’t find anything suitable so we rolled our own.
Deciding not to use floating point maths is only half the story though. Ideally we would have a mechanism in place to catch any accidental use of them. Our solution was to use the floating point inexact exception.
Bruce Dawson’s article on floating point exceptions is a highly recommended introduction to the subject (his entire series of articles on floating point numbers is excellent), it includes some simple classes to help control which floating point exceptions are enabled [10]. One of the floating point exceptions that you can enable is called the inexact exception and it fires if a floating point operation produces a result which requires rounding. As pointed out in the article this is usually not useful to game developers because floating point operations are very frequently inexact, and we are all used to writing code that allows for this fact. However, for this very specific purpose, the inexact exception is perfect as it will fire on almost any piece of code that uses floats. We do not attempt to handle or catch the exception, we simply let the debugger catch it and treat it the same way we would treat a crash or assert, as a serious bug that needs to be fixed.
On our debug builds, we enable the inexact exception (along with the rest for good measure) whenever we enter our simulation, and the exception will fire if we absent-mindedly use floats. The exception is disabled when we leave the simulation, and we use floating point maths extensively in other areas of our code-base such as rendering.
In practice we found that we rarely used floats in our simulation directly, more often we called an innocuous looking function that had some floating point operations buried deep within it. It is possible to use floating point maths without firing the inexact exception, but any floating point maths that is exact will probably exhibit consistent behaviour across different hardware anyway.
Serialization
From the outset we knew from experience where desync bugs were likely to come from. However, for all the care we took to use the correct random number generator, to avoid uninitialised variables and to tightly control input to the simulation, we knew that we would make mistakes. We decided to put systems into place to catch them in our single-player mode long before we wrote a line of actual networking code.
The main tool we used was that every time we step our simulation forward, we load the previous state, and step forward again. We then compared the two new states we produced and if there are any differences then it indicates a problem in our determinism.
In order to achieve this we wrote code to serialize and deserialize the entire simulation state. Implementing and maintaining serialization code was a moderate amount of work, however we found that being able to save and load the entire game state was useful for other reasons. We used the same serialization code to support our in-game rewind feature, to generate the checksums that detect desyncs and for some debug systems (we found it handy being able to rewind and single-step the game in debug builds).
An simpler approach to ours would be to permanently maintain a main game state and a debug state, and by stepping both forward together and comparing the result, most of the same desync bugs can be caught. The reason we chose to load the previous state each time is that our approach lets us catch bugs in our serialization code at the same time as catching our desyncs.
When we detect a difference between the two states, we found that it’s not that useful to just assert there and then, as it leaves a lot of work to be done to track down where things went wrong. To help find the cause quicker, we added code to work out which is the first out-of-sync byte in the serialised data stream. We then loaded the serialized state again, but this time we fire an assert when we get to the first desynchronized byte. That way our callstack indicated which instance of which class had gotten out of sync, this helped us track down the cause a lot faster.
Overnight CPU matches
Putting systems in place to catch desyncs fast is all very well, and most bugs that these systems are capable of catching will be caught almost immediately. However, there’s always a handful of very rare problems.

We found it was incredibly valuable to invest the time on code to let the computer run automated matches overnight. Particularly as we lacked a QA budget, it was a huge deal to know that tens of thousands of games had been run without problems. With the mechanisms we’d put in place to catch non-deterministic behaviour, our overnight single-player tests caught lots of rare event desync bugs. In addition to helping us catch determinism issues, automated testing also helped us catch other bugs throughout our codebase and we have also used it for game balancing by examining how well AI perform against each other when forced to use only specific miracles or follow specific policies.
When we finally implemented multiplayer, we extended our automated testing to our multiplayer mode, and had two machines playing matches against each other continuously overnight.
Logging/Local Player/Undefined behaviour
Despite all our care there were a small handful of desync bugs that slipped through the net. It is invaluable during development to have extensive debug logging, so that if a rare desync occurs you can pinpoint the cause without necessarily needing to repro.
Our multiplayer logging in Rapture involved serialising and writing the entire state to a logfile every frame, along with the launch data structure and any input messages. We put code in place so that it was easy to re-run the step where the machines diverged.
What slipped through
Despite our forward planning, when we finally came to implement multiplayer, there were a few desync bugs to deal with. Mostly they were caused by bugs in the networking code as it was being implemented (i.e. a failure to share the input correctly, or the accidental processing of steps before input was received).
There were a couple of instances of code in the simulation being dependent on the index of the local player, which were simple to find and fix.
We had an interesting bug caused by ambiguous sequencing that looked something like:
MyFunction(myRNG.GetRand(), myRNG.GetRand());
There is no sequence point [11] between the two calls to GetRand, so different compilers are free to do the two GetRand calls in whatever order they like. MSVC and XCode obliged by picking different orderings.
The other bug we had was a qsort callback we had implemented which sometimes returned zero. As qsort is an unstable sort, we got inconsistent results across compilers. In most of our deterministic code, if we were sorting an array then we would always have a ‘tie break’ condition (usually based on the object’s unique ID) to ensure the sort is consistent. In this one case we had omitted to do so.
After fixing these few bugs, our overnight multiplayer tests began to run smoothly, bar the odd hitch where our extensive logging led us to run out of hard drive space! After a few nights of successful overnight runs, we became pretty confident in our multiplayer code.
Conclusion
By planning ahead and implementing a number of systems in advance to ensure our code was deterministic, it meant that the vast majority of multiplayer breaking bugs were found and fixed long before a single line of multiplayer code was written.
To anyone beginning a project which will eventually utilise lockstep multiplayer, we would strongly recommend investing the time upfront to build in systems to catch common desynchronisation errors. We are confident that by implementing these systems, we saved ourselves a lot of time.
If you have any questions or comments regarding multiplayer implementation please get in touch at feedback@tundragames.com
Further Reading
[1] Lockstep as favoured by many RTS games: http://www.gamasutra.com/view/feature/131503/1500_archers_on_a_288_network_.php
[2] Server/Client with prediction as favoured by many action games: https://developer.valvesoftware.com/wiki/Latency_Compensating_Methods_in_Client/Server_In-game_Protocol_Design_and_Optimization
[3] Analysis of networking options for physics based gameplay: http://gafferongames.com/networked-physics/introduction-to-networked-physics/
[4] Planetary Annihilation, uses a modified server/client approach suitable for RTS: http://forrestthewoods.com/the-tech-of-planetary-annihilation-chronocam/
[5] Article on tracking desyncs: http://forrestthewoods.com/synchronous-rts-engines-and-a-tale-of-desyncs/
[6] Article on fixed timesteps: http://gafferongames.com/game-physics/fix-your-timestep/
[7] Floating point determinism: http://gafferongames.com/networking-for-game-programmers/floating-point-determinism/
[8] More on floating point determinism: http://randomascii.wordpress.com/2013/07/16/floating-point-determinism/
[9] More on floating point determinism: http://yosefk.com/blog/consistency-how-to-defeat-the-purpose-of-ieee-floating-point.html
[10] Article on floating point exceptions: https://randomascii.wordpress.com/2012/04/21/exceptional-floating-point/
[11] Article on sequence points in C and C++: https://en.wikipedia.org/wiki/Sequence_point
About Tundra
Tundra Games is an independent game studio based in Oxford & Colchester UK. It was founded in November 2013 by industry veterans Andrew Weinkove and Daniel Collier. We have worked on many AAA titles including Skate It, Sims 3, FIFA, Madden, Angry Birds Star Wars, Angry Birds Go and Need for Speed. We have worked for companies such as Exient, First Touch Games and Rebellion. Please contact Dan for further details at dan.c@tundragames.com.
Our game trailer can be found here, with further details and screenshots via our website.
Play the game for free on iOS here and on Android here.